Die Welt der Softwareentwicklung erlebt mit dem Wiederaufleben verschiedener KI-Techniken einige grundlegende Veränderungen. Die größte Auswirkung hat das maschinelle Lernen und insbesondere eine Untergruppe von ML, das Deep Learning. ML ist einfach eine Form der KI, die es einem System ermöglicht, anhand von Daten zu "lernen" oder "trainiert" zu werden, anstatt durch explizite Programmierung. Es ist wichtig zu wissen, dass diese Techniken nicht neu sind. Der Begriff KI wurde erstmals 1956 von John McCarthy geprägt und ist definiert als die Fähigkeit einer Maschine, intelligentes menschliches Verhalten zu imitieren. Dies ist nicht zu verwechseln mit einer Maschine, die tatsächlich über Intelligenz verfügt oder in der Lage ist, einen echten Menschen zu imitieren. KI-Systeme sind darauf ausgelegt, bestimmte menschenähnliche Fähigkeiten zu imitieren. Zum Beispiel: Sprache verstehen, bestimmte Probleme lösen, Töne/Bilder erkennen und kategorisieren, Vorhersagen treffen usw. All diese Fähigkeiten sind sehr leistungsfähig, spiegeln aber nicht die "tatsächliche" Intelligenz wider.
Es gibt verschiedene Arten von KI, die im Laufe der Jahre erforscht wurden, und die meisten sind mit dem maschinellen Lernen, das eine Renaissance erlebt, in Vergessenheit geraten. In den 90er Jahren waren die beiden Unterkategorien der KI, die am meisten erforscht wurden, ML und Expertensysteme. Expertensysteme sind eine Technik, bei der ein System mit einer Reihe von Regeln programmiert wird, anstatt explizit kodiert zu werden. Die Regeln wurden von einer "Regel-/Inferenzmaschine" verarbeitet und konnten selbst auf bescheidener Hardware Zehntausende von Ereignissen pro Sekunde verarbeiten. Das Problem war, dass die eigentlichen Regeln immer noch von Fachleuten definiert werden mussten und durch die Fähigkeit der Fachleute, alle möglichen Situationen zu erkennen, begrenzt waren. In Wahrheit handelt es sich hier nicht um KI, sondern um eine Annäherung an sie.
Maschinelles Lernen hingegen ist eine Technik, bei der die Software (das Modell) aus Daten lernt und nicht von Softwareentwicklern erstellt/kodiert oder definiert wird. Die spezielle ML-Technik, die ich in diesem Dokument beschreibe, ist als Deep Learning oder neuronale Netze bekannt. Ich möchte darauf hinweisen, dass diese Technik NICHT neu ist und ursprünglich bereits in den 60er, 70er und 80er Jahren entwickelt wurde. Der Durchbruch, der die neuronalen Netze nutzbar machte, hieß Backpropagation und wurde 1986 entdeckt/veröffentlicht. Obwohl die grundlegenden Techniken zur Implementierung neuronaler Netze gut verstanden wurden, waren sie damals aufgrund der enormen Verarbeitungsressourcen und Datensatzgrößen, die zum Trainieren der Netze erforderlich waren, leider nicht wirklich nützlich. Die einzige kommerzielle Lösung, an die ich mich erinnern kann, war ein Produkt von Computer Associates in den 90er Jahren namens Neugents (Teil ihrer Systemmanagement-Suite). Neuronale Netze wurden vom kommerziellen Sektor und dem Großteil der akademischen Welt aufgegeben, nur einige wenige Universitäten forschen noch auf diesem Gebiet, vor allem hier in Kanada.
Zurück zu den Neuronalen Netzen, die eigentlich gar nicht so kompliziert sind.
Ein neuronales Netz ist eine Ansammlung von Neuronen, die in kaskadierenden Schichten miteinander verbunden sind. Das Netzwerk beginnt mit einer Eingabeschicht und durchläuft dann versteckte Schichten, wobei die Ergebnisse schließlich die Ausgabeschicht durchlaufen. Bevor ich in die Details dieser Struktur eintauche, müssen wir zunächst klären, was unter einem Neuron zu verstehen ist (wir meinen keine lebende Zelle).
Ein Neuron ist ein Berechnungselement, das mehrere Eingaben entgegennimmt und eine einzige Ausgabe berechnet. Hier ist ein einfaches Beispiel:
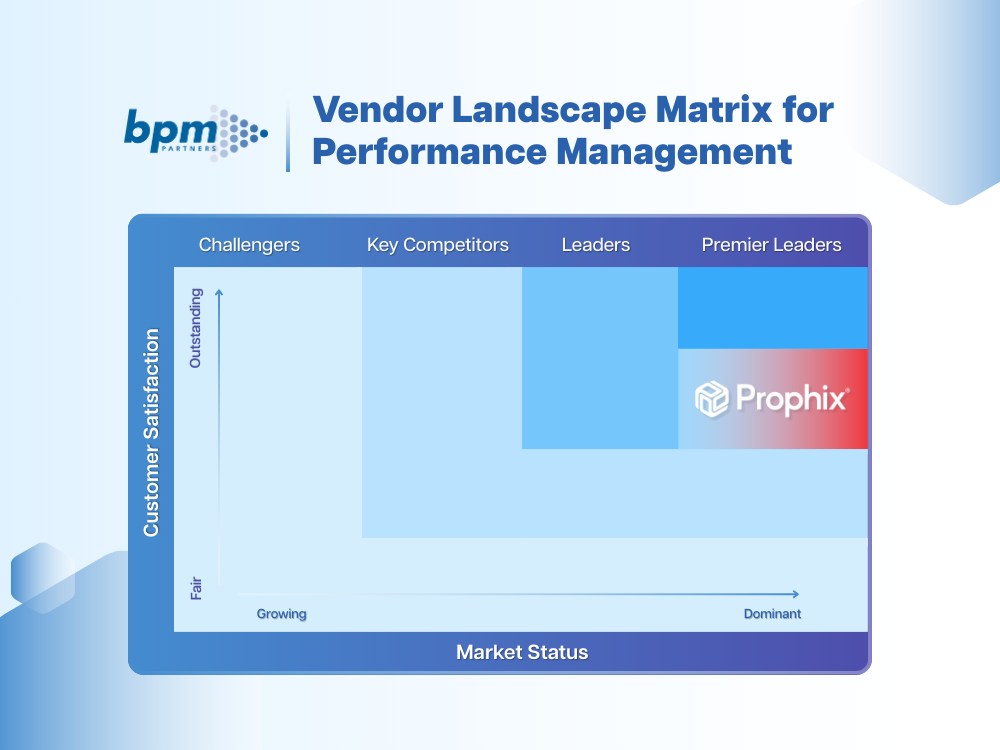
Dieses Neuron hat 2 Eingänge.
Jeder Eingang wird mit einem Gewicht multipliziert.
Die gewichteten Eingänge werden dann summiert, und ein Vorspannungswert wird dazu addiert.
Schließlich wird der unbegrenzte Wert durch eine Aktivierungsfunktion (z. B. Sigmoid) geleitet, um ihn auf einen vorhersehbaren Bereich zu reduzieren (z. B. 0 bis 1).
Hier ist ein Beispiel für ein einzelnes Neuron in Aktion:
Input 1 = 5, Input 2 = 8, W1 = 1 und W2 = 0,5, schließlich ist unser Bias 3
Unsere Ausgabe sieht wie folgt aus
Af ( ( 5 * 1 ) + ( 8 * .5 ) + 3 )
Af( 12 ) = 0,999
Versuchen wir es noch einmal mit einem anderen Satz von Eingaben, Gewichten und Verzerrungen:
Eingabe 1 =-10, Eingabe 2 = 10, W1 = 0,2, W2 = 0,1, Bias = 0,5
Ausgabe = Af( (-10 + 0.2) + ( 2 X 0.1) + 0.5)
Ausgang = Af( -8,1 ) = 3,034
Ein einzelnes Neuron ist im Wesentlichen nutzlos, abgesehen von einer interessanten mathematischen Übung, aber wenn wir mehrere Neuronen in Schichten zusammensetzen, können wir ein neuronales Netzwerk in der Form von haben:
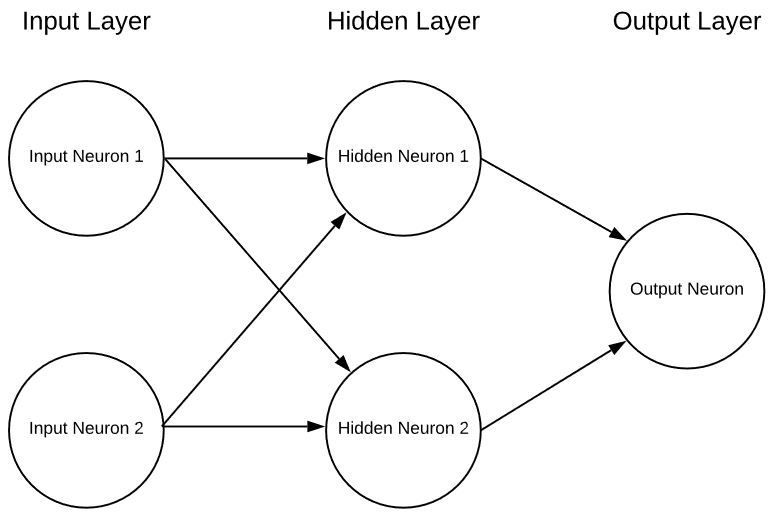
Dies ist ein extrem vereinfachtes neuronales Netz mit 2 Eingängen, einer einzigen versteckten Schicht von Neuronen und schließlich einem einzigen Ausgangsneuron. Neuronale Netze können eine beliebige Anzahl von Eingängen, Schichten und eine beliebige Anzahl von Neuronen in diesen Schichten haben. Diese Flexibilität ist das einzige ernsthafte Problem bei neuronalen Netzen. Woher weiß der Konstrukteur des Netzes, welches die optimale Anzahl von Schichten und Neuronen in diesen Schichten ist? Es gibt zwar einige Richtlinien, wo man ansetzen kann, aber die Realität ist, dass man dies nur durch Versuch und Irrtum herausfinden kann. Gegenwärtig gibt es eine Menge vielversprechender Forschungsarbeiten, die in dieser Hinsicht helfen sollen, aber wir stehen erst am Anfang.
Wie wählt man also die richtigen Gewichte und Verzerrungen für jedes Neuron aus und wie "lernt" es?
Ein tolles Thema für die nächste Folge.